While the Application State Management Wizard is capable of handling many multitudes of complex internal variable assignments within a web page, occasionally it is not able to definitively determine what section of a page caused the browser to post a field. One common case of this is with advanced Javascript events that are triggered by mouse movements or clicks.
Often, these events only contain information indicating how the user is browsing the page, and it is not necessary for Analyzer to be able to emulate them, as by default it will simply play back the user's actions exactly as they were recorded in the Testcase. However, some web applications will use these events to insert dynamic application state data that must be more closely emulated in order for the application to be successfully automated.
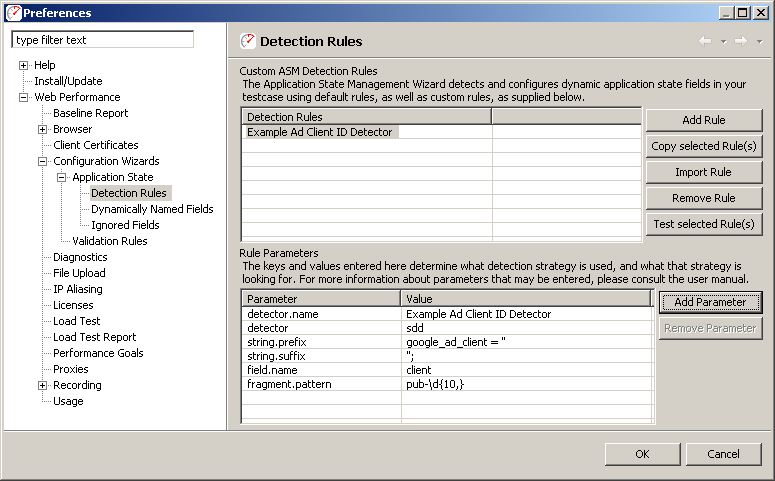
Detectors may be defined by using the "Detection Rules" preferences page. This page may be accessed by selecting Window → Preferences… and then selecting Web Performance → Configuration Wizards → Application State → Detection Rules.
To create a new rule, simply press the "Add Rule" button, and then enter the parameters for the detector. The parameters for a detector will vary based on the type of detection strategy desired. There are presently four basic types of detectors:
In addition to detectors which locate values assigned by the server, the ASM wizard understands parsers which detect embedded fields within posted content.
Single Field Detectors are designed to locate segments of code within a page for a specific field.
|
Parameter |
Value |
|---|---|
|
detector |
|
|
Example Javascript Detector |
|
|
setField('ID',' |
|
|
'); |
|
|
ID |
This should always be set to either StringDelimitedDetector or just sdd for short in order to indicate that this configuration should be treated as a single field detector
For example: detector=sdd
The name of the field that is being assigned.
The prefix of the text just up to the value of the assignment.
The suffix of the text immediately following the value of the assignment.
The confidence that this detector has that the found assignment is accurate to the transaction. If DEFINITE, this detector will replace the value by the discovered assignment. If PARTIAL, this detector will only replace the value if a DEFINITE assignment for the same field was not found. If omitted, this field defaults to PARTIAL.
The name given to this detector. If omitted this will default to the file name (less the .properties extension).
Specifies the required URL encoding strategy that a value extracted by this detector must be encoded with before being transmitted over HTTP. Possible values:
unescape.source=Probably
HTML, Maybe JavascriptMaybe
HTML, Maybe Javascript, Probably NoneA regular expression which allows this detector to detect only a dynamic fragment of the value of the field. For more information on the behavior of this field, please see the Fragmented Value Detectors section.
Both of the String Delimited Detectors can be made to search for fragmented values (instead of complete values) by adding the Parameter "fragment.pattern". The value of this field should be a regular expression, which must match the isolated fragment of the field.
To understand how this works, consider an example field "client" with the value "ca-pub-1971486205579989". Now, let us suppose that the HTML document contains a Javascript fragment:
google_ad_client = "pub-1971486205579989";
In this case, only part of the value of the field has been declared in the source of the script. The full value is determined at a later point in time, by concatenating the prefix "ca-" with the variable value declared. In order to play back this case, the detector should only detect the dynamic fragment. This may be accomplished in our example using the following detector configuration:
|
Parameter |
Value |
|---|---|
|
detector |
sdd |
|
detector.name |
Example Ad Client ID Detector |
|
string.prefix |
google_ad_client = " |
|
string.suffix |
"; |
|
field.name |
client |
|
fragment.pattern |
pub-\d{10,} |
In this case, the additional field "fragment.pattern" allows this detector to use a dynamic value defined by the HTML to replace "pub-1971486205579989" within the value "ca-pub-1971486205579989".
Like the String Delimited Detector, this detector requires both a prefix and a suffix. However, the variable name may be substituted anywhere into the prefix or suffix by including the string "{0}" (without the quotes)wherever the name should be substituted. Single quotes (') must also be entered twice where used.
For example: Suppose the fields TX_ID and TS_ID were assigned in a page using a snippet of javascript code written as:
setField('TX_ID','1234'); setField('TS_ID','56789');
Then the Variable Delimited Detector could be configured to detect both of these assignments (1234 and 56789, respectively) with the following configuration:
|
Parameter |
Value |
|---|---|
|
detector |
|
|
detector.name |
Example wildcard Javascript function assignment detector |
|
string.prefix |
setField(''{0}'','' |
|
string.suffix |
''); |
This should always be set to either VariableDelimitedDetector or just vdd for short in order to indicate that this configuration should be treated as a variable field detector
For example: detector=vdd
The prefix of the text just up to the value of the assignment.
The suffix of the text immediately following the value of the assignment.
A regular expression constraining which fields are subject to detection based on their names. If present, fields that do not match this pattern are omitted from this detector. If not present, all fields are examined by default.
the confidence that this detector has that the found assignment is accurate to the transaction. If DEFINITE, this detector will replace the value by the discovered assignment. If PARTIAL, this detector will only replace the value if a DEFINITE assignment for the same field was not found. If omitted, this field defaults to PARTIAL.
The name given to this detector. If omitted this will default to the file name (less the .properties extension).
Specifies the required URL encoding strategy that a value extracted by this detector must be encoded with before being transmitted over HTTP. Possible values:
unescape.source=Probably
HTML, Maybe JavascriptMaybe
HTML, Maybe Javascript, Probably NoneA regular expression which allows this detector to detect only a dynamic fragment of the value of the field. For more information on the behavior of this field, please see the Fragmented Value Detectors section.
In addition to string delimited detectors, it is also possible to use a Regular Expression to capture field values from a page. This form of detection rule provides greater control over the search used to locate the dynamic value. Additionally, the search pattern can contain multiple capture groups, allowing a single search to extract values for multiple fields in a single pass.
For example, suppose our testcases present a list of slots, where we generally need to select the first slot that is open. The server may send some HTML in the form of:
<li><a href="viewSlot.do?slot=1">Slot 1</a>, Status: Closed</li> <li><a href="viewSlot.do?slot=2">Slot 2</a>, Status: Open</li> <li><a href="viewSlot.do?slot=3">Slot 3</a>, Status: Open</li>
We create a Regular Expression detector to handle the field "slot" in new testcases where the user should select the first "Open" slot:
|
Parameter |
Value |
|---|---|
|
detector |
RegExAssignmentDetector |
|
detector.name |
Example Regular Expression Detector for "Open" slots |
|
search.pattern |
<li><a href="viewSlot.do\?slot=(\d+)">Slot \1</a>, Status: Open</li> |
|
groups.count |
1 |
|
group1.name.pattern |
slot |
|
content_type.pattern |
text/html.* |
This should always be set to either RegExAssignmentDetector or just read for short in order to indicate that this configuration should be treated as a regular expression detectors
For example: detector=read
The regular expression to search for. Values extracted by the expression are represented as capture groups
the confidence that this detector has that the found assignment is accurate to the transaction. If DEFINITE, this detector will replace the value by the discovered assignment. If PARTIAL, this detector will only replace the value if a DEFINITE assignment for the same field was not found. If omitted, this field defaults to PARTIAL.
Specifies a regular expression which constrains on which pages the
detector will look to find the value. If this pattern is specified, then
this detector will only search for field assignments within pages that
have a Content-Type containing this expression. For example: content_type.pattern=text/html.*
will cause the detector to only search within HTML documents. If this
expression is not specified, the detector will search all available transactions
for a match.
The number of capture groups specified in the "search.pattern". If this value is omitted, it assumed to be 1.
Specify this pattern to constrain by name which fields group N will be considered a valid assignment for. For example, consider a testcase with two fields:
|
name |
value |
| quantity | 1 |
| ctrl$00 | 1 |
And a search pattern search.pattern=<input name="ctrl\$\d{2}"
value="(\d*)" />
Using this pattern, the value "1" will be extracted, which
can match either field. By specifying group1.name.pattern=ctrl\$\d{2},
this detector will only assign the extracted value to the field ctrl$00.
Specify this pattern to constrain by recorded value which fields group N will be considered a valid assignment for.
The name given to this detector. If omitted this will default to the file name (less the .properties extension).
Specifies the required URL encoding strategy that a value extracted by this detector must be encoded with before being transmitted over HTTP. Possible values:
unescape.source=Probably
HTML, Maybe JavascriptMaybe
HTML, Maybe Javascript, Probably NoneNote that group 0 implicitly matches the entire pattern. The entire pattern is not considered a valid value for any field, unless either "group0.name.pattern", or "group0.value.pattern" is specified.
Sticky Regular Expression Detectors are an extended version of regular expression detectors. These detectors are capable of invoking the datasource matching capabilities of the regular expression extractor, and can construct complex regular expressions from "templates" that contain pre-made regular expression fragments. All of the options of regular expression detectors are also available with sticky regex, plus the following:
Should be set to StickyRegExAssignmentDetector (sread for short).
Optionally replaces search.pattern. A metapattern contains characters referring to a metapattern template, where each character represents a regular expression fragment.
Name of the template file. Template files are kept in the dfc_templates directory alongside the dfc directory that contains all detection rules.
Indicates whether or not capture group number N should be considered "sticky." If a capture group is sticky, it is not eligable to be extracted into a user state variable.
Instead, the original recorded value will be matched against the sticky capture group at extraction time.
For example, we could use the (simplistic and technically incorrect) regular expression (\w++)\(\(d++)\) to capture a javascript-style method call taking a single integer.
In this example, capture group 1 would be sticky. Load Tester would then know to remember the name of the method and look for it in future responses.
Sticky regular expression template files consist primarily of key-value pairs that describe regular expression fragments that can be concatenated to form complex regular expressions.
For example, to recreate the javascript method call recognizer described above, we could use the metapattern f(d) and a template reading:
f = (\w++)
capture.f=true
sticky.f=true
( = \(
) = \)
d = (\d++)
capture.d=true
This annotation allows you to construct many regular expression extractors based on a common set of fragments. Furthermore, the identification of capture groups and sticky capture groups allows the sticky regular expression detector to automatically count and identify the capture groups in any given metapattern.
Some applications may utilize dynamic components not just in the form of traditional query parameters and field values, but also the path segments of the individual URLs. For example, a request for the URL http://mysite.com/widgets/14697302/index.html may need to be dynamically replaced for the path segment 14697302 for each virtual user.
Detectors are presently limited to searching for a path segment within the location header of a previous redirect response. For further configuration options, please contact support.
A sample configuration file for this form of URL would look like
|
Parameter |
Value |
|---|---|
|
detector |
dpsd |
|
segment.pattern |
(\d{6,}) |
the type of detector to use. This style of detector may be specified as DynamicPathSegmentDetector (dpsd for short).
a regular expression defining the criteria for what path segments
are eligible for dynamic replacement. This detector will first ignore
all path segments that do not entirely match this expression. Each dynamic
component within the expression must be within a capturing group to then
be eligible for replacement. In the above example, the pattern (\d{6,})
reads:
Look for a segment containing at least 6 decimal digits, and only decimal digits, and then replace the entire segment.
To replace just the numeric component within a path segment such
as 64315_A, you could use the expression: (\d{5})(?>_\w)?
the name given to this detector. If omitted this will default to the file name (less the .properties extension).
the confidence that this detector has that the found assignment is accurate to the transaction. If DEFINITE, this detector will replace this path segment from the first matching redirect it finds, if the redirect appears to redirect to this URL or a similarly based URL. If omitted, this field will default to PARTIAL.
A name and value pattern match can be used to detect and parse embedded fields from a posted value. ASM can then look for assignments to the embedded fields using the detectors listed above. For example, suppose
the application uses a field called query with a value of {x: 1, y: 2}. In this example, we can write a rule to treat X and Y as two separate fields.
|
Parameter |
Value |
|---|---|
| detector | PatternizedNameAndValueUsageDetector |
| detector.pattern | (\w+): (\d+) |
| parent.value.pattern | \{.+\} |
the type of detector to use. This style of detector may be specified as PatternizedNameAndValueUsageDetector (pnavud for short).
A Regular Expression to search for. The name and values to extract are specified as capture groups from the pattern.
A Regular Expression which filters which fields are parsed for this sub pattern by name. Only fields which have a matching name are examined for sub fields using this rule. If this value is omitted, then no filtering will be applied by name.
A Regular Expression which filters which fields are parsed for this sub pattern by value. Only fields with matching values are examined for sub fields using this rule. If this value is omitted, then no filtering will be applied by value.
A number which identifies which capture group in the "detector.pattern" should be used as the name of the embedded field. If this value is omitted, the name is assumed to come from capture group 1.
A number which identifies which capture group in the "detector.pattern" should be used as the value of the embedded field. If this value is omitted, the value is assumed to come from capture group 2.
An anonymous name and value pattern match can be used to detect and parse individual components from a posted value, such as a list. ASM can then look for assignments to the embedded fields
using the detectors listed above. For example, suppose the application uses a field called query with a value of {1, 2, 3}.
In this example, we can write a rule to treat 1, 2, and 3 each as separate fields.
|
Parameter |
Value |
|---|---|
| detector | PatternizedAnonymousUsageDetector |
| detector.pattern | \d+ |
| parent.value.pattern | \{.+\} |
the type of detector to use. This style of detector may be specified as PatternizedAnonymousUsageDetector (paud for short).
A Regular Expression to search for. If there are 1 or more capture groups in the pattern, then each capture group is treated as an individual field. Otherwise, every instance of the whole pattern is treated as an individual field.
A Regular Expression which filters which fields are parsed for this sub pattern by name. Only fields which have a matching name are examined for sub fields using this rule. If this value is omitted, then no filtering will be applied by name.
A Regular Expression which filters which fields are parsed for this sub pattern by value. Only fields with matching values are examined for sub fields using this rule. If this value is omitted, then no filtering will be applied by value.